Das Ranking in den Suchmaschinen erfordert eine Website mit fehlerfreiem technischen SEO. Glücklicherweise kümmert sich das Yoast SEO-Plugin (fast) um alles auf Ihrer WordPress-Site. Wenn Sie jedoch wirklich das Beste aus Ihrer Website herausholen und sich weiterhin von der Konkurrenz abheben möchten, sind einige Grundkenntnisse in technischem SEO ein Muss. In diesem Beitrag werde ich eines der wichtigsten Konzepte der technischen Suchmaschinenoptimierung erläutern: die Crawlbarkeit.
Was ist der Crawler nochmal?
Eine Suchmaschine wie Google besteht aus einem Crawler, einem Index und einem Algorithmus. Der Crawler folgt den Links. Wenn der Crawler von Google Ihre Website findet, liest er sie und der Inhalt wird im Index gespeichert.
Ein Crawler folgt den Links im Web. Ein Crawler wird auch als Roboter, Bot oder Spinne bezeichnet. Es geht rund um die Uhr im Internet. Sobald es zu einer Website kommt, speichert es die HTML-Version einer Seite in einer riesigen Datenbank, die als Index bezeichnet wird. Dieser Index wird jedes Mal aktualisiert, wenn der Crawler Ihre Website besucht und eine neue oder überarbeitete Version davon findet. Je nachdem, wie wichtig Google Ihre Website für Sie hält und wie viele Änderungen Sie an Ihrer Website vornehmen, kommt der Crawler mehr oder weniger häufig vor.
Und was ist Crawlbarkeit?
Die Crawling-Fähigkeit hat mit den Möglichkeiten zu tun, die Google zum Crawlen Ihrer Website bietet. Crawler können von Ihrer Site aus blockiert werden. Es gibt verschiedene Möglichkeiten, einen Crawler von Ihrer Website zu blockieren. Wenn Ihre Website oder eine Seite Ihrer Website blockiert ist, sagen Sie zu Googles Crawler: “Kommen Sie nicht hierher”. Ihre Website oder die entsprechende Seite wird in den meisten Fällen nicht in den Suchergebnissen angezeigt.
Es gibt einige Dinge, die verhindern könnten, dass Google Ihre Website crawlt (oder indiziert):
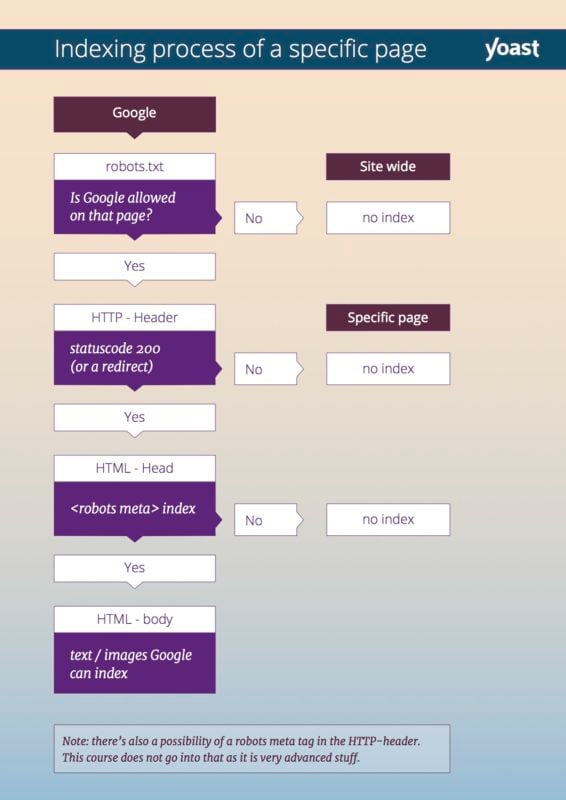
- Wenn Ihre robots.txt-Datei den Crawler blockiert, gelangt Google nicht zu Ihrer Website oder bestimmten Webseite.
- Vor dem Crawlen Ihrer Website überprüft der Crawler den HTTP-Header Ihrer Seite. Dieser HTTP-Header enthält einen Statuscode . Wenn dieser Statuscode besagt, dass eine Seite nicht vorhanden ist, wird Ihre Website von Google nicht gecrawlt. Im Modul über HTTP-Header unserer technischen SEO-Schulung erfahren Sie alles darüber.
- Wenn das Roboter-Meta-Tag auf einer bestimmten Seite die Suchmaschine daran hindert, diese Seite zu indizieren, crawlt Google diese Seite, fügt sie jedoch nicht ihrem Index hinzu.
Dieses Flussdiagramm kann Ihnen helfen, die Prozess-Bots zu verstehen, die beim Versuch, eine Seite zu indizieren, folgen:
Möchten Sie alles über Crawling erfahren?
Obwohl die Crawlbarkeit nur die Grundlagen der technischen Suchmaschinenoptimierung sind (sie hat mit all den Dingen zu tun, die es Google ermöglichen, Ihre Website zu indizieren), ist sie für die meisten Menschen bereits ziemlich fortgeschritten. Trotzdem, wenn Sie blockieren – vielleicht sogar ohne es zu wissen! – Crawler von Ihrer Website, Sie werden nie einen hohen Rang in Google. Wenn Sie SEO ernst nehmen, sollte dies für Sie von Bedeutung sein.
Wenn Sie wirklich alle technischen Aspekte der Crawlbarkeit verstehen möchten, sollten Sie unbedingt unser technisches SEO-Training lesen . In diesem SEO-Kurs lernen Sie, wie Sie technische SEO-Probleme erkennen und lösen (mit unserem Yoast SEO-Plugin ).